L’infrastruttura Big Data di Lepida è stata avviata in ambiente di produzione, dopo un periodo di studio e di sperimentazione e una valutazione delle possibili soluzioni alternative, tra le quali è stato scelto il Cloud Oracle e in particolare il servizio Oracle Big Data Service (BDS) costituito da una distribuzione Cloudera ingegnerizzata e adattata per il deploy automatico all’interno dell’infrastruttura Cloud. L’architettura ha quindi subito alcune modifiche, dovendosi adattare ai nuovi strumenti messi a disposizione dal Cloud.
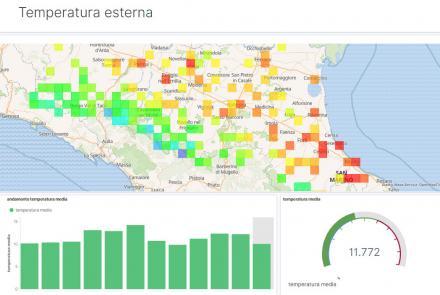
L’infrastruttura rende possibile l’ingestion di flussi di natura diversa, per ognuno dei quali occorre realizzare un modulo ad hoc. I dati sono elaborati in step successivi, tenendo conto della normativa in tema di privacy. I dati raw rimangono memorizzati nel Cloud per il periodo di tempo previsto a seconda del tipo di dato, e sono sottoposti a diversi gradi di elaborazione che prevede, ad esempio, aggregazioni e incroci con diversi dataset per estrarre l’informazione in funzione dell’output desiderato. Al momento, sono acquisiti i log degli Access Point (AP) che espongono la rete EmiliaRomagnaWiFi e i dati rilevati dai sensori presenti nella rete SensorNet. Per i dati provenienti dalla rete SensorNet il processo di elaborazione, a valle dell’eventuale pseudo-anonimizzazione dei dati personali, prevede l’arricchimento di alcune informazioni e quindi il filtraggio e le aggregazioni ai fini delle visualizzazioni desiderate. È quindi possibile mostrare le medie geolocalizzate su mappe dei valori rilevati - temperatura, umidità, livelli delle polveri sottili, precipitazioni etc. - e correlare le diverse misure. I dati degli AP richiedono un processamento più articolato, che parte dalla cattura e trasformazione dei log ricevuti in eventi singoli. Si passa al filtraggio dei soli eventi di interesse e alla pseudo-anonimizzazione dei dati personali, precedente alla memorizzazione dei dati, fino all’arricchimento con le informazioni di geolocalizzazione e all’aggregazione dei dati. Il risultato di questi processi di distillazione è un’informazione di più alto livello, capace di rispondere a domande come ad esempio: quali nuovi dispositivi si connettono alla rete per la prima volta e il loro numero, quanti dispositivi si connettono giornalmente, quali spostamenti compiono gli utenti all’interno della regione.
Per permettere la fruizione del dato e quindi dei risultati, i dati vengono memorizzati e visualizzati attraverso due strumenti: ElasticSearch/Kibana e Metabase con DB Postgres, entrambi installati on-prem. Le dashboard realizzate rispondono visualmente a queste domande monitorando i dati e le loro relazioni, valutandone sia l’andamento nel tempo sia la distribuzione geografica. Le informazioni e i grafici visualizzati avranno diverse tipologie di destinatari: quella dell’Ente per il controllo dei dati e come strumento decisionale; quella del cittadino a fini informativi per il monitoraggio dei dati resi disponibili dall’ente stesso.




